
Azure Synapse Analytics was originally called Azure Data Warehouse. As thename suggests, it was built as a particular type of SQL database engine for storing large amounts of data that could then be queried by an analytics service such as Databricks.
The solution has been built out to include many new features and therefore was rebranded to highlight that it now does far more.
Azure Synapse Analytics is now a fully integrated service that enables you to ingest, transform, and analyze data. It can be used as a complete replacement for Azure Data Factory and Azure Databricks or used with them.
Azure Synapse Analytics provides access to two engines, SQL and Spark, and the SQL engine can be serverless or provisioned. As with Azure SQL Database using SQL serverless offers significant cost efficiencies for periodic workloads; however, the provisioned option may be better for continual availability and guaranteed performance levels.
As an integrated service, the Azure Synapse interface is very similar to that of Azure Data Factory. You can use it to create pipelines and the same activities, as you can see in the following screenshot:
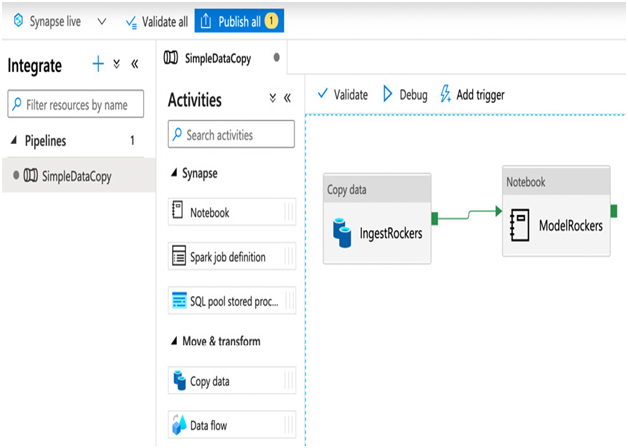
Figure 13.8 – Combining Azure Data Factory pipelines and Azure Synapse Analytics notebooks
As with Azure Data Factory, you use IRs for running some activities, and again these can be Azure-hosted or self-hosted.
As mentioned, Azure Synapse Analytics includes a SQL engine that can create queries and analyze data. Using the familiar Transact-SQL (T-SQL) language, data can be ingested, aggregated, and queried using a SQL pool. SQL pools run in a similar way to Apache Spark clusters, in that jobs are distributed among multiple worker nodes to enable much faster processing times.
Alternatively, data can be loaded, transformed, and analyzed using Apache Spark clusters by building notebooks, similar to Azure Databricks.
Choosing Azure Synapse Analytics over Azure SQL Database provides many benefits due to SQL pools’ serverless nature and the underlying architecture of using distributed nodes. However, choosing this service over Azure Databricks may not seem as obvious.
Although both Azure Databricks and Azure Synapse Analytics use Spark clusters, Azure Synapse Analytics only supports version 2.4. The underlying runtime is based on the open source version of Spark. Conversely, Azure Databricks supports Spark version 3.1, and it includes additional components that provide greater performance and reliability. Because of this, Azure Databricks can perform up to 50x faster.
Azure Synapse Analytics, however, has support for .NET applications running on Spark, includes data pipeline orchestration, and consists of the SQL Pool engine. Therefore, the choice between the two can come down to the type of work you are performing, the level of performance required, and the toolsets you are used to using.
Leave a Reply